Efficient Machinery Assignment with a Production Scheduler
2008.05.12
Q. In our factory, we have several hundred machines. Some of the
machines are the same but there are also other machines with slightly
different specifications as well. The production scheduling is done
manually by hand and the allocation of machines is decided in the
same way. With scheduling decided in a fixed style even when
alternative machines are free, operations are halted inefficiently. Please
tell us a way of production scheduling that efficiently allocates machinery.
Make Use of a Production Scheduler and Arrange
the Data
A. Generally, there are multiple lines and machines that can handle
each item and process and depending on the machine, the operation speed is
different.
Using the FCS (Finite Capacity Scheduling)
software, let's try to schedule the condition of this question.
For the production scheduling, first we set
the master data (Scheduler Diagram 1):
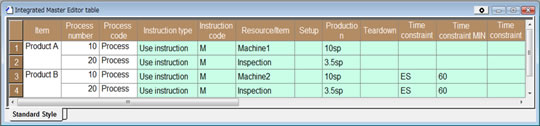 Scheduler Diagram 1 Set up the master data for the production scheduling (set up so that Process 1 can only manufacture using Machine1). ProductA is produced using Process 1 and Process 2. Process 1 can only manufacture using Machine1 and it takes 10 seconds to produce one unit (Production = 10sp : Second per Piece). Process 2 is an inspection process that takes 3.5 seconds to process 1 unit. Scheduler Diagram 1 Set up the master data for the production scheduling (set up so that Process 1 can only manufacture using Machine1). ProductA is produced using Process 1 and Process 2. Process 1 can only manufacture using Machine1 and it takes 10 seconds to produce one unit (Production = 10sp : Second per Piece). Process 2 is an inspection process that takes 3.5 seconds to process 1 unit. |
Input numerous production orders (Scheduler Diagram 2) and the result is that the machines used are biased (Scheduler Diagram 3).
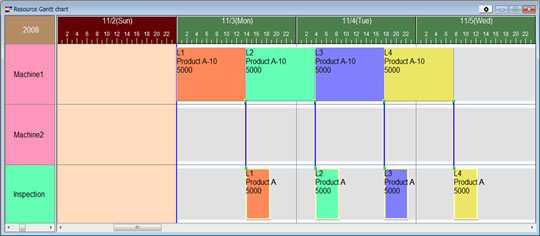 Scheduler Diagram 3 Production Scheduling result in the case that you don't use alternative resources. Because Process 1 has assigned all the operations to Machine1 even if Machine2 could manufacture ProductA it won't be allocated any operations. Thus order L4 will be completed around mid-day on 5th Nov. Scheduler Diagram 3 Production Scheduling result in the case that you don't use alternative resources. Because Process 1 has assigned all the operations to Machine1 even if Machine2 could manufacture ProductA it won't be allocated any operations. Thus order L4 will be completed around mid-day on 5th Nov. |
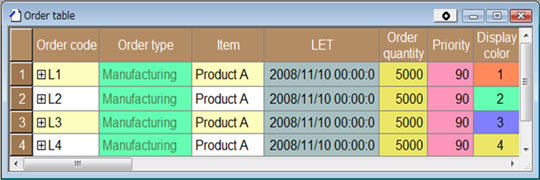 Scheduler Diagram 2 sets the orders for production scheduling. There are four orders in total (L1, L2, L3, L4). Order L1 has a due date of 10th Nov to produce 5000 units. Scheduler Diagram 2 sets the orders for production scheduling. There are four orders in total (L1, L2, L3, L4). Order L1 has a due date of 10th Nov to produce 5000 units. |
If we say that Machine2 is an alternative machine for Process1, then we can't say that this is a production scheduling result that makes effective use of Machine2.
If the volume of set data for the production scheduling is low, then even if a human thinks about it, it's clearly obvious that it would be better to move a number of operations for Process 1, the top bar in Scheduler Diagram 3, to Machine2. However, if there were hundreds of machines and thousands or tens of thousands of operations, then to input all of this data into the production scheduling software would be a massive undertaking. Even more so if there was a complex relationship with how which machines could handle which items.
Now, let's set the master data so that the operations for Process 1 are automatically allocated to Machine2 as well (Scheduler Diagram 4)、
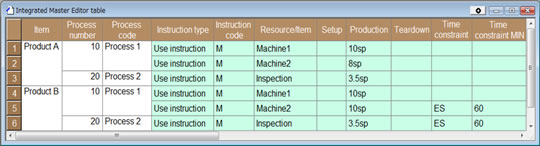 Scheduler Diagram 4: Set up alternate resource so that not only Machine1 but Machine2 can also process Process 1 for ProductA. The Production value is 8sp. and create our production schedule. The result is that, the load for every machine is balanced and the finished date is earlier. (Scheduler Diagram 5) Scheduler Diagram 4: Set up alternate resource so that not only Machine1 but Machine2 can also process Process 1 for ProductA. The Production value is 8sp. and create our production schedule. The result is that, the load for every machine is balanced and the finished date is earlier. (Scheduler Diagram 5) |
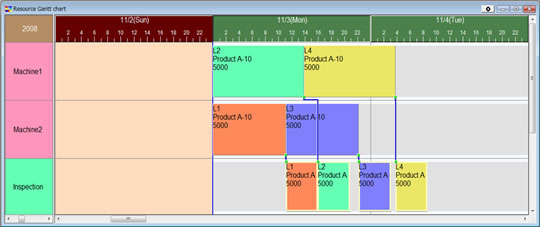 Scheduler Diagram 5 Production Scheduling Result: The case where operations for Process 1 are automatically allocated to Machine2 (alternative resource). Orders L1 and L3 have been automatically moved to Machine2 which is faster as seen in the shortened bar's length. Order L4 will be finished around midday on 4th Nov. This is one day faster than the result in Scheduler Diagram 3. With this scheduling, the planning creation parameters have been specified so that the load for Process 1 is balanced between Machine 1 and Machine 2. Scheduler Diagram 5 Production Scheduling Result: The case where operations for Process 1 are automatically allocated to Machine2 (alternative resource). Orders L1 and L3 have been automatically moved to Machine2 which is faster as seen in the shortened bar's length. Order L4 will be finished around midday on 4th Nov. This is one day faster than the result in Scheduler Diagram 3. With this scheduling, the planning creation parameters have been specified so that the load for Process 1 is balanced between Machine 1 and Machine 2. |
The volume of data that needs to be set up for production scheduling at a real factory is enormous and thus the job of setting up the data is very difficult. For example, if at your factory you have 1000 types of products with each operation process consisting of an average of 10 processes, then you'll have to set up 1000 x 10 = 10,000 lines of data.
Although the organization of data needed for production scheduling is a very hard task, the value of the results generated is extremely high.
In the situation where the production time and setup time is solely managed by the head of the production scheduling team, then the it's gonna be a big problem should that person got sick and be hospitalized for a long time or worse, leave the company. In order for your company to organize your data, then I recommend that the first step should be that you consider Finite Capacity Scheduling (Production Scheduling).